|
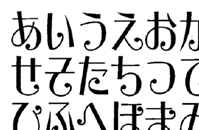 STEP
1 STEP
1
初期のオリジナルデザインは、漢字と組み合わせることなど深く考えていなかったので、このように長体3番ぐらいでデザインされていました。
|
|
 STEP
2 STEP
2
長体のままでは、漢字との組み合わせが不自由なので、正体になるようにタテ・ヨコの比率を変えて、右図のようにスキャンした。
なにしろ古い原図なので本物の原稿はボロボロで使い物にならず「えれがんと」が収録されている「ひらがなカタカナ集1(マール社)」を使用した。
私が作者だからこういうことが可能だが、個人使用目的以外での第三者のこのような行為は許されないので気をつけて下さい。
|
|
 STEP
3 STEP
3
スキャンしたデータを、イラストレータ(Adobe社Illustrator)上でデザインの変更をしながら、ペンツールを使いトレスする。ヨコ画とタテ画など、別々の図形のまま制作したほうが、微妙な変更作業が楽になると思う。
|
|
STEP
4
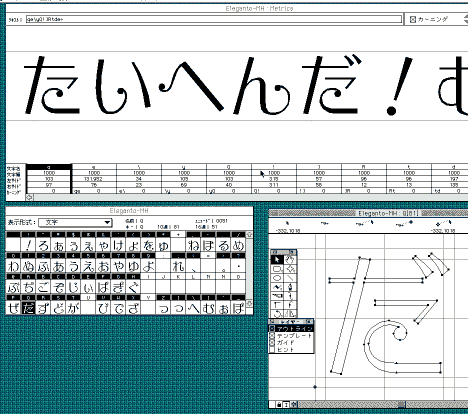
フォントグラファー(macromedia社Fontographer)に1文字づつデータを移し、文字の位置や大きさなどをメトリクスウインドで確認しながら整え、ある程度の水準まで仕上がったら、濁音や拗促音類も作る。
必要なだけの字数がデザインできたらPSフォントファイルを作成し、さまざまなサイズ・体裁のテストプリントを出力する(下右図)。
出力されたテストプリントを参考に、修整・変更・テストプリントを繰り返し、最も細いウエイトの「えれがんとEL」を完成させる。
|
  |
|
STEP
5
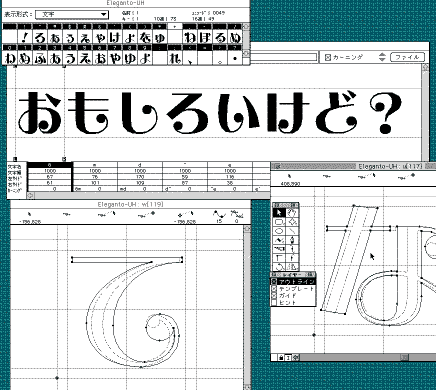
完成した「えれがんとEL」のデータを利用しながら、最も太いウエイトの「えれがんとU」を1文字づつデザインする(グレーの線画がEL。この書体の場合、横線の太さは変えない)。
なぜ細い書体のデータを利用するのか? 後でELとUのブレンド作業をする時に、各オブジェクトのポイントの数や階層に違いがあると、うまくいかず面倒なためだ。
STEP
4と同様にテストプリント(下右図)を見ながら修整を繰り返し、「えれがんとU」を完成させる。
|
  |
|
STEP
6
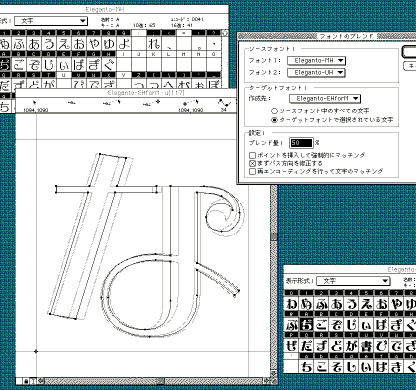
完成した「EL」と「U」の中間の太さを、フォントグラファーのブレンドコマンド(50%)で発生させ、えれがんと「M」を作る。
しかし両極端の太さの、ELとUから作られた「M」の形状は、かなり混乱しており、そのままでは使い物にならない文字もあるので、1文字づつ丁寧に形とデータを整える(もう一度ELとUのデータを変更することもある)。
最初から「M」を自分で作成したほうが…とも考えられるが、自分がデッサンしたこともないウエイトの文字をソフトウエアが計算で作り上げるのを見るのは、今までの苦労も忘れられるほど楽しい時間なのだ(グレーの線画がELとU、実線がM)。
その後、ステップ4と同様にテストプリント(下右図)を見ながら修整を繰り返し、えれがんと「M」を完成させる。
|
  |
|
STEP
7
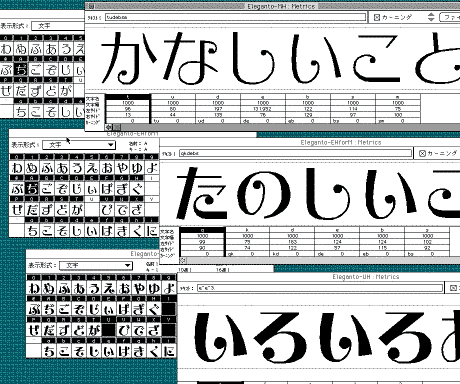
フォントグラファーでは各ウエイト間で99段階(4ケタ以上の段階まで可能なようだがデータの確認が出来ないし、意味もない…)のブレンドが可能なので、「EL」「M」「U」の3ウエイトの書体が揃うと(私の場合この工程に1〜2年の月日が過ぎる)201段階のウエイトの書体が制作可能になる。
これで、どんな明朝系漢字書体にでも太さや字面の大きさを、ぴったり合わせた「えれがんと書体」が抽出(下右図)できるデジタルデータベースの完成だ。
|
|
|
|
STEP
8
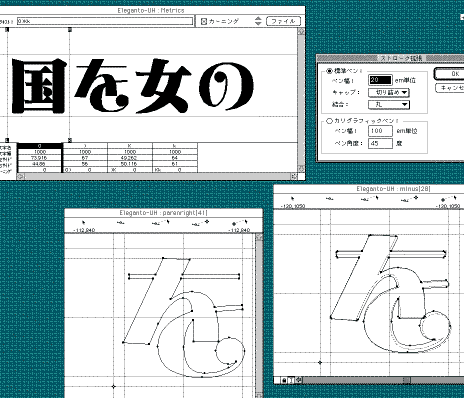
しかし、私の想像したウエイトの範囲を超えた書体も世の中には存在するわけで、フォントワークス社のマティスUの漢字の場合は、「えれがんとU」でも太さ・黒さとも足りなかったし、エレメントの末端が丸く処理してあり、「えれがんと」のシャープな末端では、マティスの漢字にはマッチしなかった。
|
 |
|
 そこで「えれがんとU」を96%縮小し、エレメントに20/1000emの角丸の太さをつけ」マッチさせた(右図、上の行は作業前の状態。下の行がマッチさせたもの)。 そこで「えれがんとU」を96%縮小し、エレメントに20/1000emの角丸の太さをつけ」マッチさせた(右図、上の行は作業前の状態。下の行がマッチさせたもの)。
|
